









即日起,模型已經(jīng)在 Github 和 Huggingface 等開源社區(qū)上線,同時模型API也在騰訊云官網(wǎng)正式上線,支持快速接入部署。
這是業(yè)界首個13B級別的MoE開源混合推理模型,基于先進的模型架構,Hunyuan-A13B表現(xiàn)出強大的通用能力,在多個業(yè)內(nèi)權威數(shù)據(jù)測試集上獲得好成績,并且在Agent工具調(diào)用和長文能力上有突出表現(xiàn)。
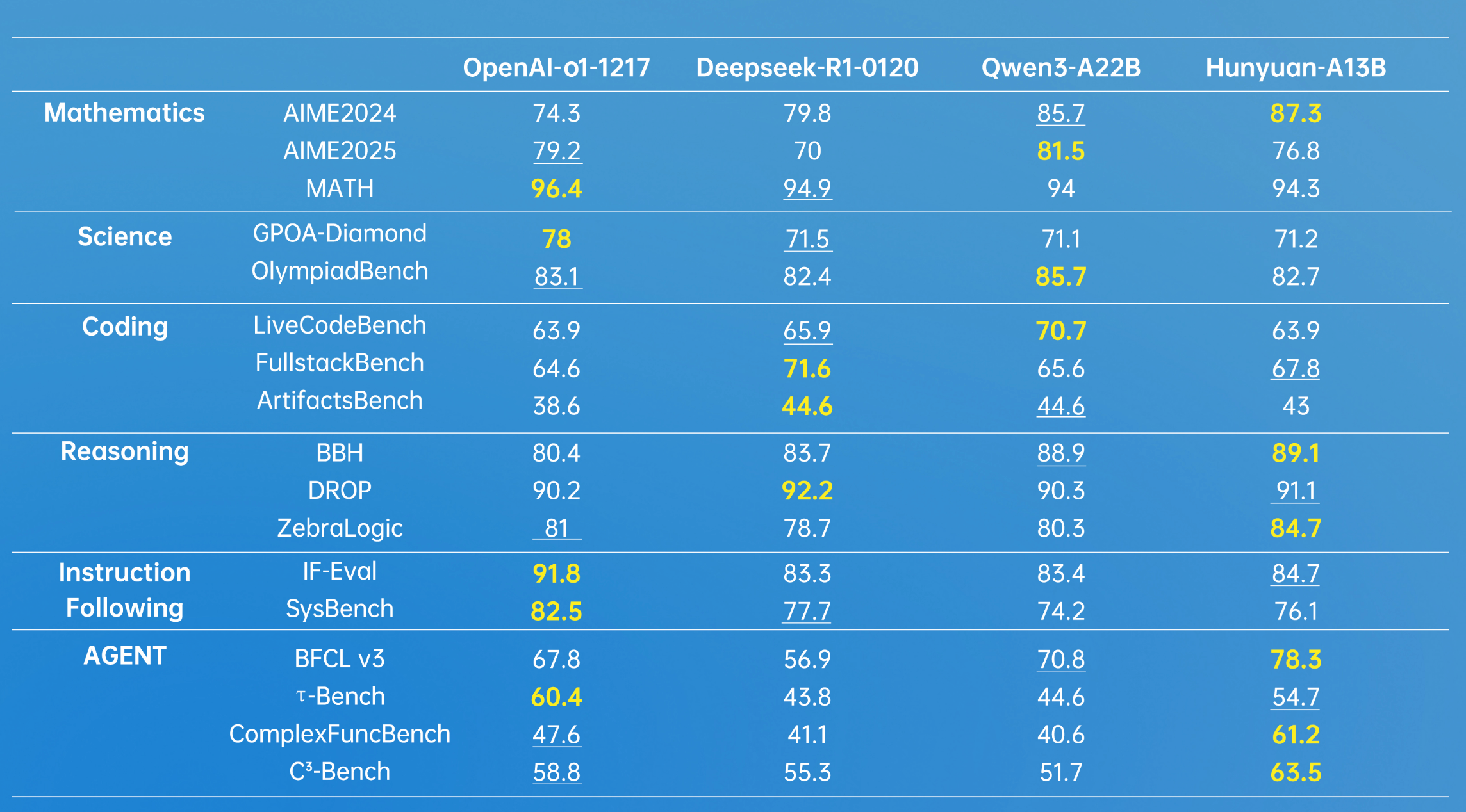
*加粗為最高分,下劃線表示第二名,數(shù)據(jù)來源于模型各個公開的測試數(shù)據(jù)集得分
對于時下熱門的大模型Agent能力,騰訊混元建設了一套多Agent數(shù)據(jù)合成框架,接入了MCP、沙箱、大語言模型模擬等多樣的環(huán)境,并且通過強化學習讓Agent在多種環(huán)境里進行自主探索與學習,進一步提升了Hunyuan-A13B的效果。
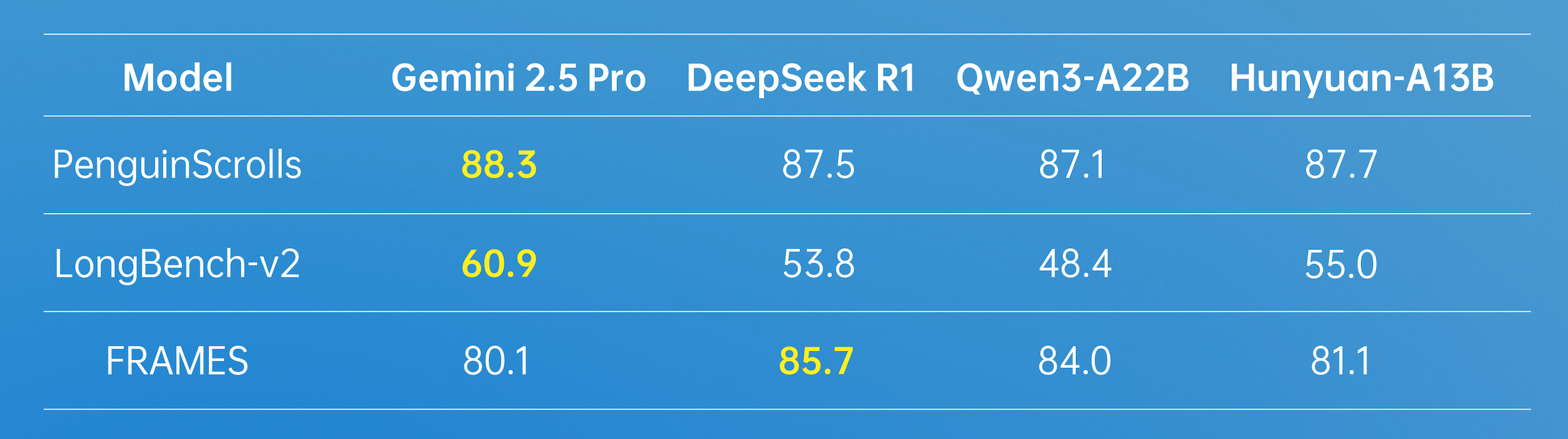
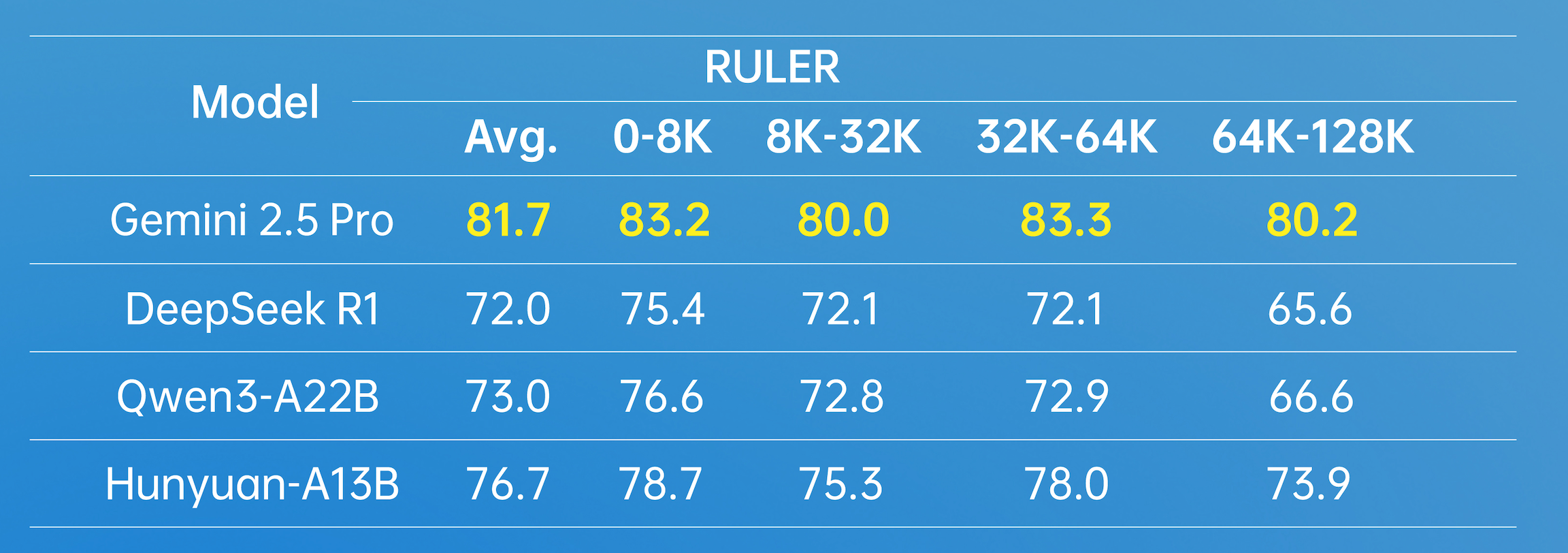
在長文方面,Hunyuan-A13B支持256K原生上下文窗口,在多個長文數(shù)據(jù)集中取得了優(yōu)異的成績。
在實際使用場景中,Hunyuan-A13B模型可以根據(jù)需要選擇思考模式,快思考模式提供簡潔、高效的輸出,適合追求速度和最小計算開銷的簡單任務;慢思考涉及更深、更全面的推理步驟,如反思和回溯。這種融合推理模式優(yōu)化了計算資源分配,使用戶能夠通過加think/no_think切換思考模式,在效率和特定任務準確性之間取得平衡。
Hunyuan-A13B模型對個人開發(fā)者較為友好,在嚴格條件下,只需要1張中低端GPU卡即可部署。目前,Hunyuan-A13B已經(jīng)融入開源主流推理框架生態(tài),無損支持多種量化格式,在相同輸入輸出規(guī)模上,整體吞吐是前沿開源模型的2倍以上。
Hunyuan-A13B 集合了騰訊混元在模型預訓練、后訓練等多個環(huán)節(jié)的創(chuàng)新技術,這些技術共同增強了其推理性能、靈活性和推理效率。
預訓練環(huán)節(jié),Hunyuan-A13B 訓練了20T tokens的語料,覆蓋了多個領域。高質(zhì)量的語料顯著提升了模型通用能力。此外,在模型架構上,騰訊混元團隊通過系統(tǒng)性分析,建模與驗證,構建了適用于 MoE 架構的 Scaling Law 聯(lián)合公式。這一發(fā)現(xiàn)完善了MoE 架構的 Scaling Law 理論體系,并為 MoE 架構設計提供了可量化的工程化指導,也極大的提升了模型預訓練的效果。
后訓練環(huán)節(jié),Hunyuan-A13B采用了多階段的訓練方式,提升了模型的推理能力,同時兼顧了模型創(chuàng)作、理解、Agent等通用能力。

圖:Hunyuan-A13B后訓練四個步驟
為更好的提升大語言模型能力,騰訊混元也開源了兩個新的數(shù)據(jù)集,以填補行業(yè)內(nèi)相關評估標準的空白。其中,ArtifactsBench用于彌合大語言模型代碼生成評估中的視覺與交互鴻溝,構建了一個包含 1825個任務的新基準,涵蓋了從網(wǎng)頁開發(fā)、數(shù)據(jù)可視化到交互式游戲等九大領域,并按難度分級以全面評估模型的能力;C3-Bench針對Agent場景模型面臨的三個關鍵挑戰(zhàn):規(guī)劃復雜的工具關系、處理關鍵的隱藏信息以及動態(tài)路徑?jīng)Q策,設計了1024條測試數(shù)據(jù),以發(fā)現(xiàn)模型能力的不足。
Hunyuan-A13B模型是騰訊內(nèi)部應用和調(diào)用量最大的大語言模型之一,有超過 400+ 業(yè)務用于精調(diào)或者直接調(diào)用,日均請求超1.3億。本次進行升級更新并對外開源,是繼混元large后混元大語言模型推出的又一重要開源模型,參數(shù)更小,但是性能和效果實現(xiàn)了大幅的提升。接下來,騰訊混元也將推出更多尺寸、更多特色的模型,將更多實踐技術與社區(qū)共享,促進大模型開源生態(tài)的繁榮。
騰訊混元堅定擁抱開源,持續(xù)推進多尺寸、多場景的全系模型開源,旗下圖像、視頻、3D、文本等多種模態(tài)基礎模型已全面開源。未來,混元計劃推出多尺寸混合推理模型,從0.5B到32B的dense模型,以及激活13B的MoE模型,適配企業(yè)與端側不同需求,混元圖像、視頻、3D等多模態(tài)基礎模型及配套插件模型也將持續(xù)開源。















 京公網(wǎng)安備 11010502049343號
京公網(wǎng)安備 11010502049343號